today, i would to share to you about chapter 2 in computer science (computer system)
 |
computer system has two subtopics which is system concept
and number system and representation

Input, processing, output and storage are the activities that perfomed by computer. We must know how to draw information processing cycle. Parellel shape is for input and output, rectangle is for process and cylinder shape is for storage.

Data can be represented by using 2 binary digits : 1(on) - 0(off). 8 bits combined together to represent a data.
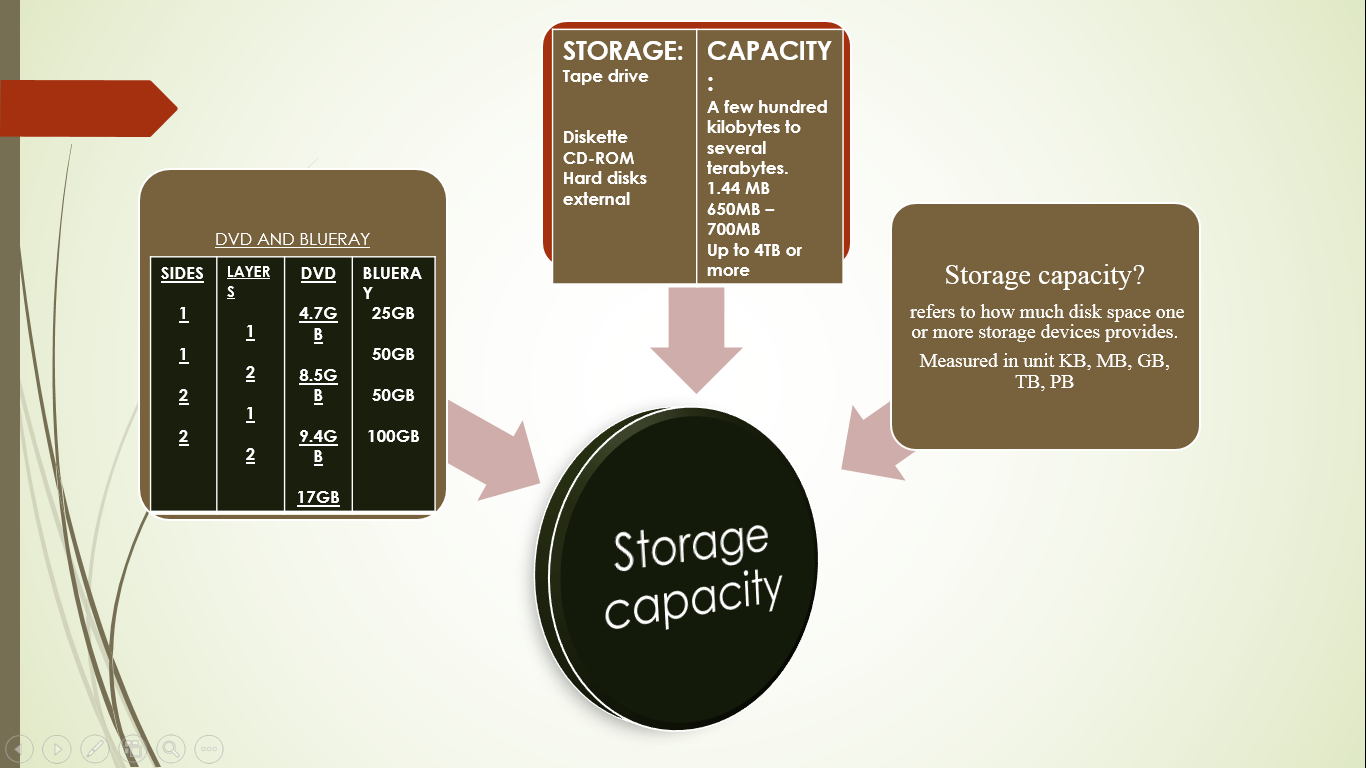
storage capacity - The amount of data a
storage device such as a disk or tape can hold. Storage capacity is measured in
kilobytes (KB), megabytes (MB), gigabytes (GB) and terabytes (TB). See
space/time, magnetic disk, magnetic tape and optical disc.

When working with any kind of digital electronics in which
numbers are being represented, it is important to understand the different ways
numbers are represented in these systems.
It is cumbersome for humans to deal with writing, reading
and remembering individual bits, because it takes many of them to represent
even fairly small numbers. A number of different ways have been developed to
make the handling of binary data easier for us. The most common is hexadecimal.
In hexadecimal notation, 4 bits (a nibble) are represented by a single digit.
There is obviously a problem with this since 4 bits gives 16 possible
combinations, and there are only 10 unique decimal digits, 0 to 9. This is
solved by using the first 6 letters (A..F) of the alphabet as numbers. The
table shows the relationship between decimal, hexadecimal and binary.
|
Decimal
|
Hexadecimal
|
Binary
|
|
0
|
0
|
0000
|
|
1
|
1
|
0001
|
|
2
|
2
|
0010
|
|
3
|
3
|
0011
|
|
4
|
4
|
0100
|
|
5
|
5
|
0101
|
|
6
|
6
|
0110
|
|
7
|
7
|
0111
|
|
8
|
8
|
1000
|
|
9
|
9
|
1001
|
|
10
|
A
|
1010
|
|
11
|
B
|
1011
|
|
12
|
C
|
1100
|
|
13
|
D
|
1101
|
|
14
|
E
|
1110
|
|
15
|
F
|
1111
|

So far we have seen the different ways that binary can be
used to store numbers. As we already know, most computers can only understand
binary and we often need to store alpha-numeric text (numbers, letters and
other characters). To do this a computer will use a coding scheme. The most popular
coding schemes are ASCII, EBCDIC and Unicode.
You'll need to know how each works and the benefits and drawbacks of using
them.

There are two reasons to use ASCII. First, we need some way
to represent characters as binary numbers (or, equivalently, as bitstring
patterns). There's not much choice about this since computers represent
everything in binary.The other reason we use ASCII is because of the letter
"S" in ASCII, which stands for "standard". Standards are
good because they allow for common formats that everyone can agree on.Another character representation that was used (especially
at IBM) was EBCDIC, which stands for Extended Binary Coded Decimal
Interchange Code (yes, the word "code" appears twice). This
character set has mostly disappeared. EBCDIC does not store characters
contiguously, so this can create problems alphabetizing "words".Thus, a new character set called Unicode is now becoming
more prevalent. This is a 16 bit code, which allows for about 65,000 different
representations. This is enough to encode the popular Asian languages (Chinese,
Korean, Japanese, etc.). It also turns out that ASCII codes are preserved. What
does this mean? To convert ASCII to Unicode, take all one byte ASCII codes, and
zero-extend them to 16 bits. That should be the Unicode version of the ASCII
characters.

so, here is the comparison between ASCII, EBCDIC AND Unicode.
that's all for today. hope this post would help you in computer science. bye.
ok
ReplyDelete